
ComfyUI-Searge-LLM地址:
https://github.com/SeargeDP/ComfyUI_Searge_LLM
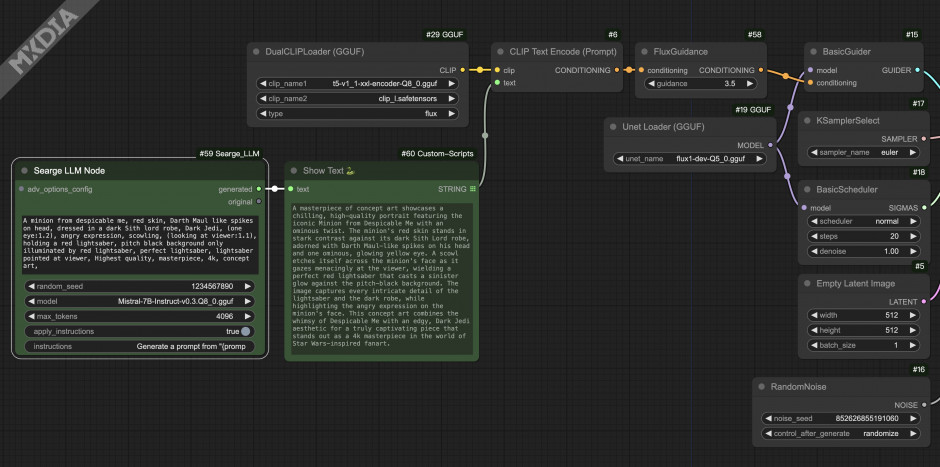
ComfyUI 的提示生成器或提示改进节点,利用语言模型的强大功能将提供的文本到图像提示转换为更详细和改进的提示。

作用很简单,输入一个简单的prompt,Searge-LLM可以扩写、完善和细化描述词。
比如我输入:an apple logo
Searge-LLM输出:The subject of this minimalist digital design is an iconic Apple logo, designed in a sleek and modern style. The familiar image consists of the interlocking silhouette of an apple with a bite taken out of it, set against a monochrome background that accentuates its clean lines and bold simplicity. The colors are kept to a minimal palette of white for the logo and either black or another neutral shade for the background, creating an image that is both timeless and instantly recognizable. This design would be ideal as a digital badge, social media profile picture, or branding element in various digital marketing materials.
使用也很简单,只有两个节点,配合prompt预览节点,就可以工作起来了。
安装有几个注意的地方:
- manager里搜索Searge-LLM,安装即可。
- 下载模型 https://huggingface.co/MaziyarPanahi/Mistral-7B-Instruct-v0.3-GGUF/tree/main 中下载 Mistral-7B-Instruct-v0.3.Q4_K_M.gguf(4G),这个是Q4量化模型,比较小,如果MAC是16G可以下载Mistral-7B-Instruct-v0.3.Q8_0.gguf(7.7G),理论上模型越大,输出结果质量越高。
- 将下载的模型放到ComfyUI/models/llm_gguf 目录下,没有的话创建一下。
- 安装llama-cpp,启动终端,(进入ComfyUI的python环境)执行 pip install llama-cpp-python
- 重新启动comfyUI
使用方式:
添加Searge LLM Node,generated连接Show Text节点,输出到CLIP的text输入节点即可。
text:语言模型要处理的输入文本。
model:您希望使用的 models/llm_gguf 中的模型的目录名称。
max_tokens:生成文本的最大令牌数,可根据您的需要进行调整。
apply_instructions:
instructions:语言模型生成提示的说明。它支持占位符 {prompt} 从文本输入中插入提示。例: Generate a prompt from "{prompt}"
Searge-LLM还有一个高级节点Searge Advanced Options Node 提供了一系列可配置的参数,允许对文本生成过程和模型行为进行精确控制。
Temperature (temperature):控制文本生成过程中的随机性。较低的值使模型的预测更有信心,从而减少输出的可变性。较高的值会增加多样性,但也会引入更多的随机性。默认值:1.0。
Top-p (top_p):此参数也称为原子核采样,用于控制累积概率分布中断。该模型将仅考虑抽样概率最高的前 p% 代币。减小此值有助于通过避免低概率标记来控制生成质量。默认值:0.9。
Top-k (top_k):限制生成的每个步骤考虑的最高概率标记的数量。值为 0 表示没有限制。此参数可以防止模型过于狭隘地关注顶部选择,从而促进生成文本的多样性。默认值:50。
Repetition Penalty (repetition_penalty): :调整输出中已出现的标记的可能性,从而阻止重复。大于 1 的值会惩罚已使用的标记,从而使它们不太可能再次出现。默认值:1.2。
使用起来还有很多可能性,关于mac上运行ai工具的问题,可以咨询微信号:mxdiaZ
